RAG PDF Chatbot with Phi-2/TinyLlama
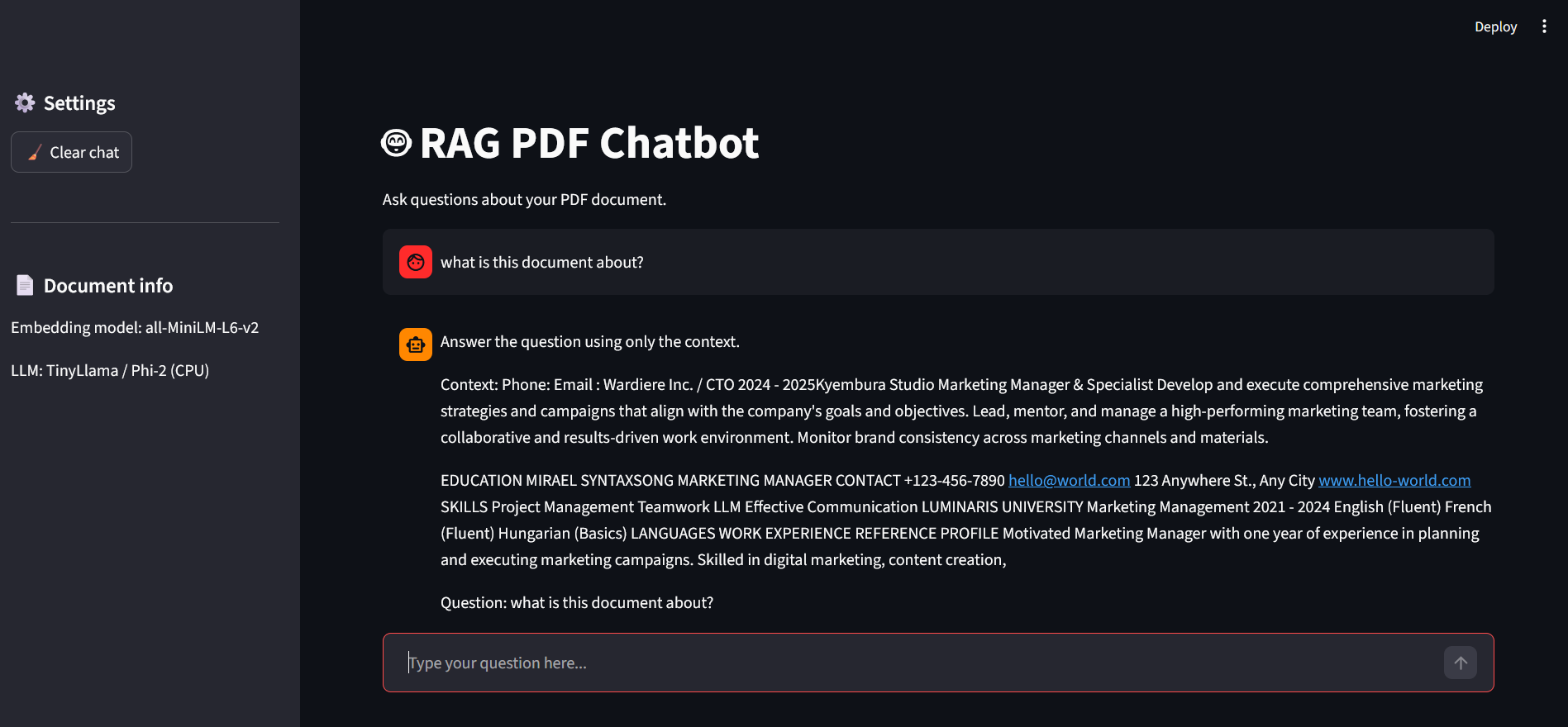
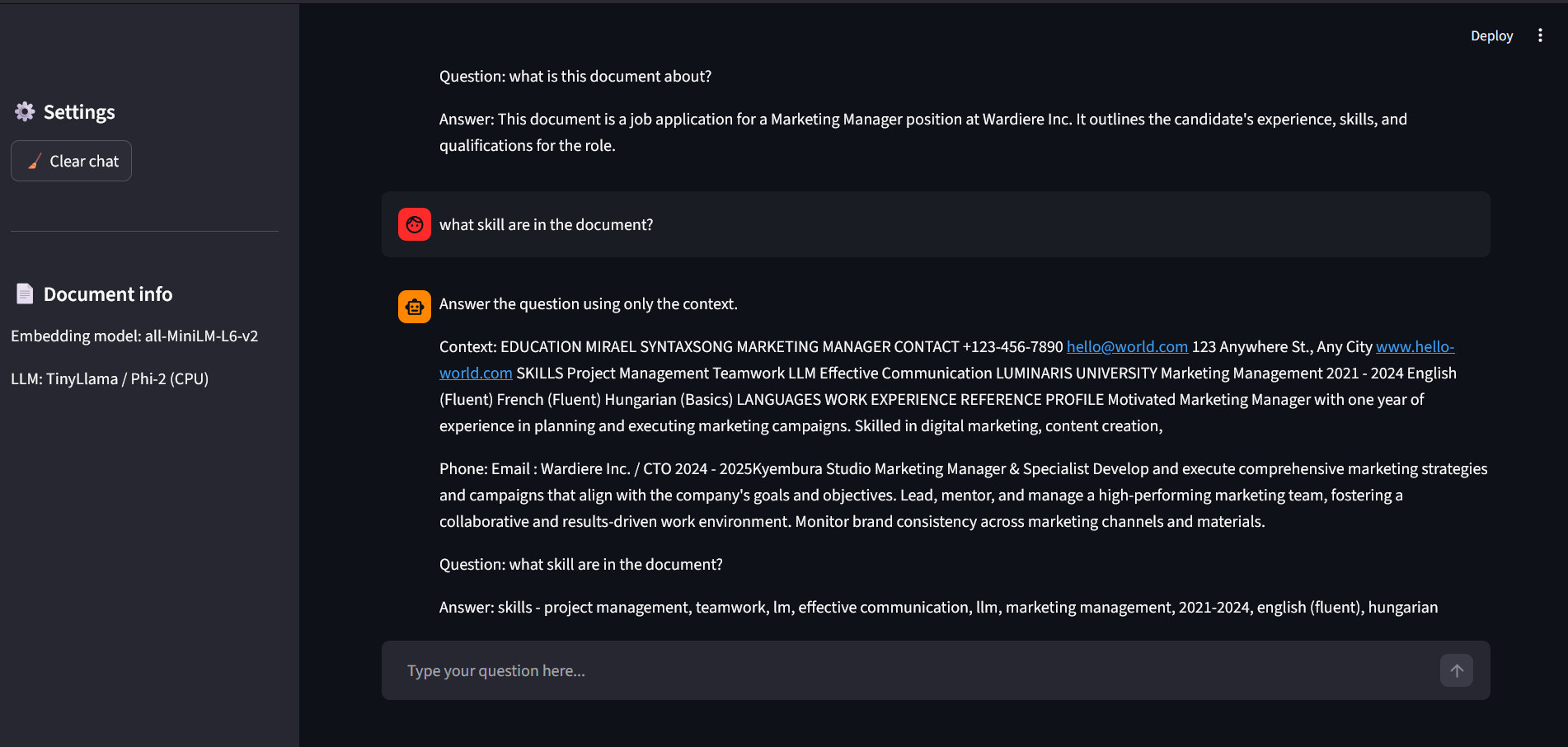
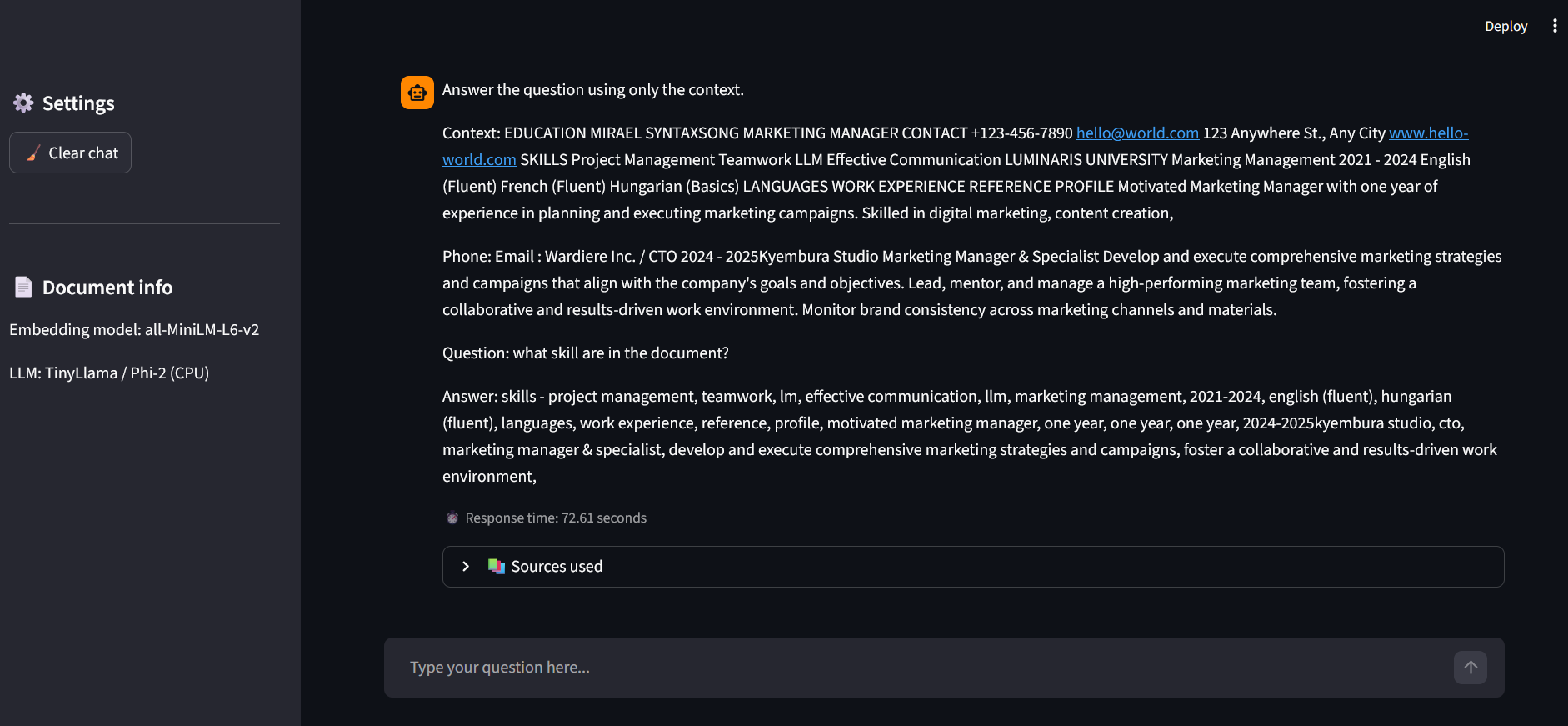
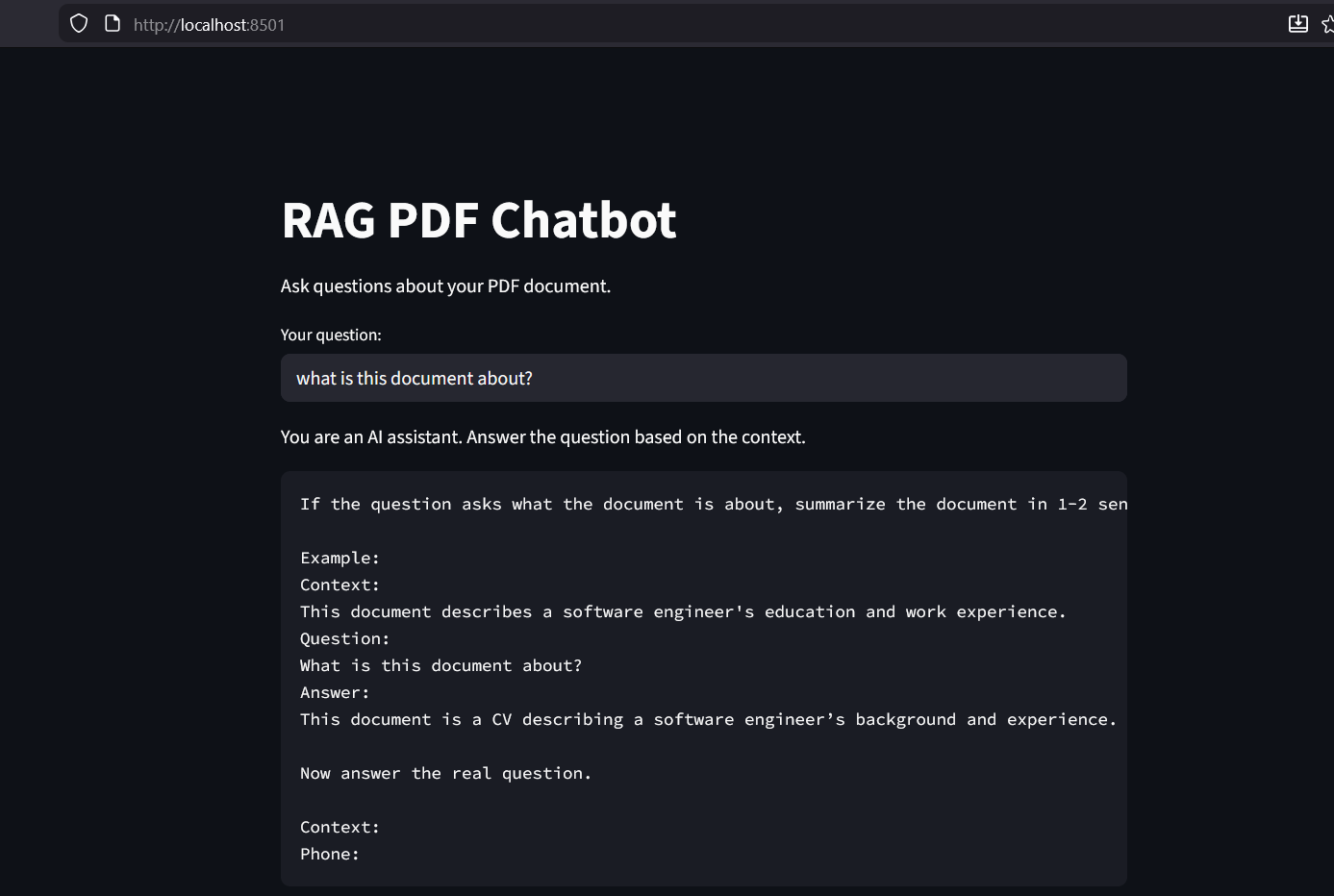
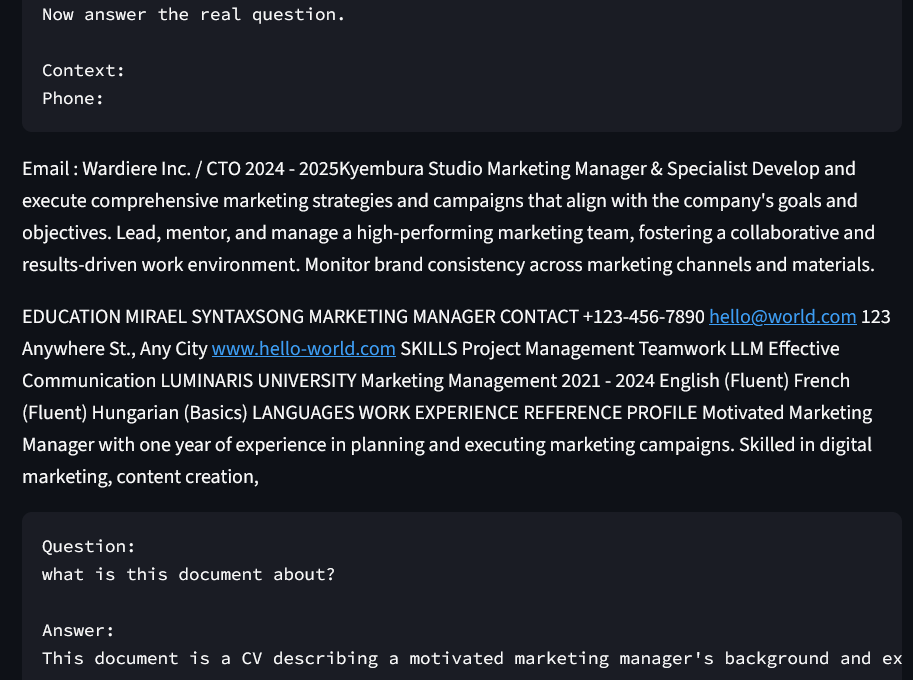
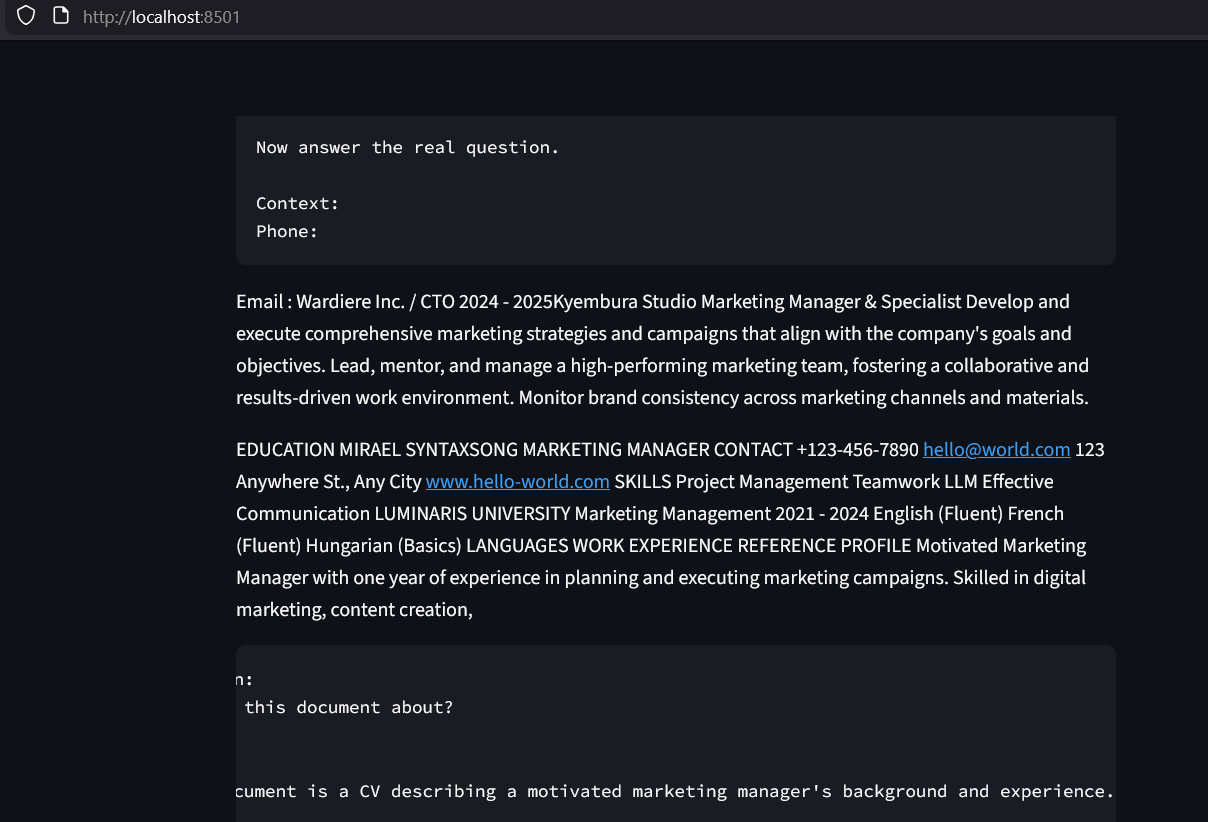
A full-stack RAG (Retrieval-Augmented Generation) application built to process and query unstructured PDF data. The system implements a sophisticated pipeline: documents are partitioned into semantic chunks, transformed into high-dimensional embeddings, and indexed in a FAISS vector store. At query time, the system performs semantic retrieval to provide grounded context to local Small Language Models (TinyLlama or Phi-2), ensuring accurate answers while maintaining 100% data privacy.
Key Features
- End-to-End RAG Pipeline: Seamless integration of document loading, semantic chunking, and vector indexing.
- Semantic Vector Search: Utilizes FAISS and Sentence-Transformers for high-speed, context-aware information retrieval.
- Local SLM Integration: Optimized for privacy and performance using TinyLlama and Microsoft's Phi-2 models via HuggingFace.
- Explainable AI (XAI): Features a source-tracking mechanism that highlights exactly which document segments were used to generate each answer.
- Interactive UI: A polished Streamlit-based chat interface with session persistence and real-time latency monitoring.
- Optimized Text Processing: Implements Recursive Character Splitting with overlap to preserve semantic continuity across chunks.
Tech Stack
PythonLangChainFAISS (Vector Database)StreamlitHuggingFace (Transformers)Phi-2 / TinyLlama (LLMs)Sentence-Transformers (Embeddings)PyPDF
Screenshots